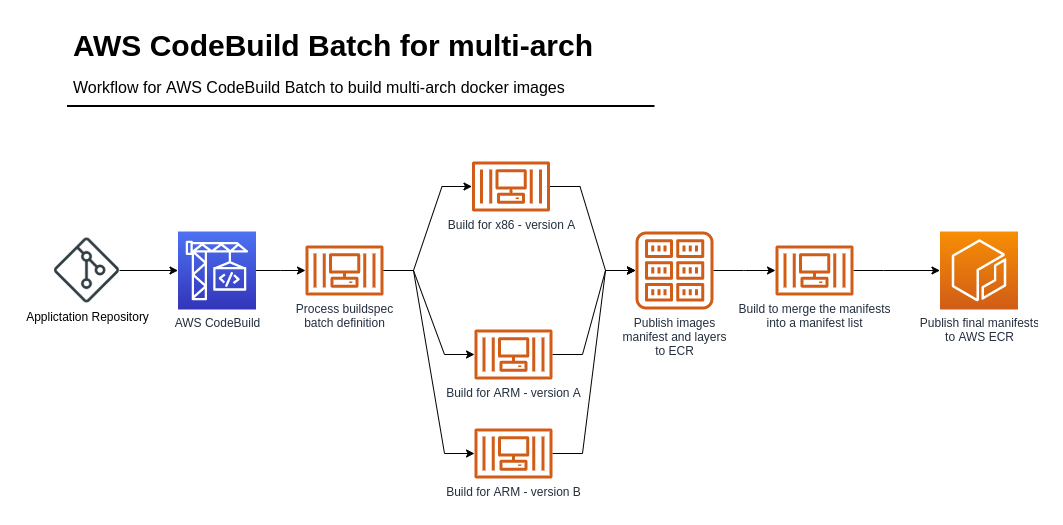
Automated ECR Scans & Reports with ecr-scan-reporter
Situation analysis
#TLDR; A lot of images built and used, no notifications, and no automated re-scan after X amount of time.
With the rapid adoption of containerized technologies, and the ease of use that allows anyone today to publish images for internal or public consumption, has grown the necessity to scan and inspect security of our images.
Although DockerHub and other Docker images repositories allow certain vendors to release official images, there is no doubt that unaware developers or cloud engineers would jump at the opportunity to grab the first image that does the job for them and move on.
But that is not the only issue at hand: with the adoption of DevOps lifecycles, a lot of repositories simply grow bigger by day, as the pipelines build new images everyday.
On AWS ECR, you can set to perform a scan of the image when pushed, but, not all OSes are supported yet for scanning, and, most importantly, there is no notification integration built-in to let the teams know the outcome of the scan with other services. Which could lead to vulnerabilities to be shipped into the newest version of your images. If you rely on humans to actively go and check for the scan result when you provided them with a pipeline that does everything else for them, chances are, they won't.
Furthermore, by having tens of new images a day published can lead to simply to loosing complete track of what is in your repository. So after even just a few days, these images you recently pushed could in fact contain vulnerabilities that on the day you scanned them, weren't in the CVE (or other security reports sources) at the time, and one of these images could very well be the one you have running in production.
Welcome ECR Scan Reporter
#TLDR; ECR Scan Reporter | Documentation
ECR Scan Reports being a built-in feature of AWS ECR, which is free, uses Clair, and publishes to EventsBridges events when scans are in progress, failed or complete, we have a very easy integration that allows us to capture and feed into AWS Lambda (or other services).
Also, EventsBridge allowing us to create cronjobs like executions (previously into AWS CloudWatch Events) we could trigger a scan for all the images of all our repositories on a regular basis to ensure that we keep up with the images we previously published.
ECR Scan Reporter aims to provide these features in cost effective way using AWS Lambda and fully automated, that users can configure as they need it.
Actively scanning regularly
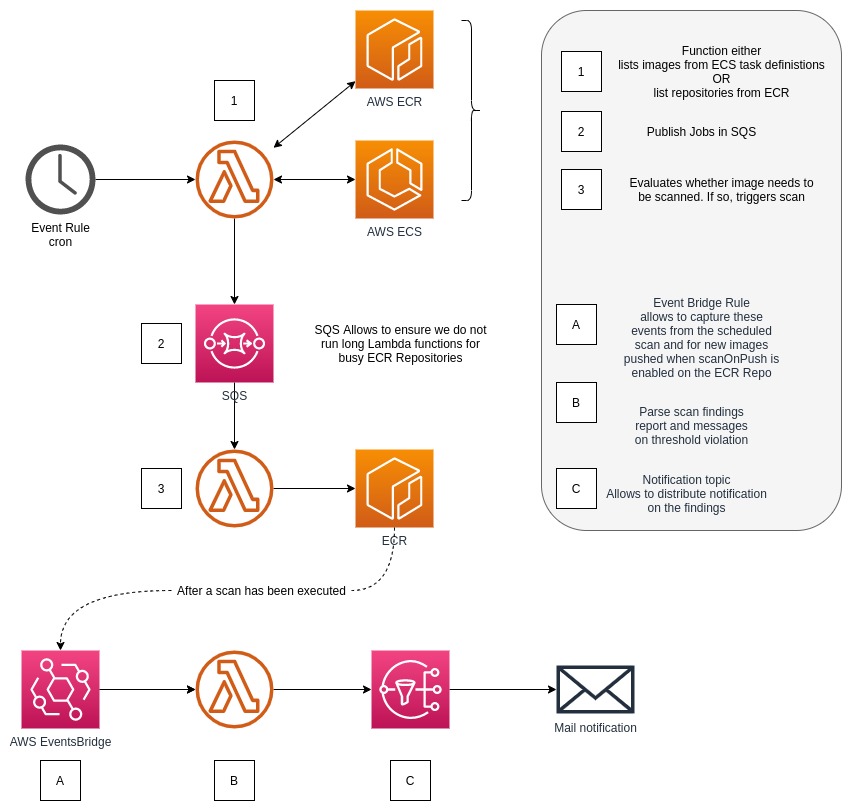
As described above, we then have 2 functions which work together. The first one, will list all the repositories in the Registry (note that these are region based), and then send into SQS a list of the repositories that you want to scan.
Hint
The Function that lists the repositories can be provided a regular expression to select which repositories to scan.
A second Lambda function, triggered by Lambda via SQS, receives the repositories to scan. The reason for splitting the two functions is to enable parallelism and keep the execution time of these lambda functions very short.
That second function is then going to list the images of the given repository, and describe these in order to get information details about the scan.
If the image was never scanned, it will trigger a scan. If the image was scanned, it will then evaluate how long ago was that last scan, and if above the user defined "expiry duration", will then trigger a new scan for that image.
Hint
The default duration is 7 days, and is completely configurable by the user.
Hint
For each vulnerability level (CRITICAL, HIGH, MEDIUM and LOW) the user can override the threshold value for the scan.
Note
Some repositories do not have immutable tagging, leading to some images being untagged, but still in the repository. ECR Scan Reporter will then fall back onto using the Image Digest instead of the image tag in subsequent API calls.
Reporting findings
As mentioned in the situation analysis, there is not (yet! ... AWS has a habit to make my solutions obsolete) a feature to integrate into notifications systems easily yet to report on the security findings once the scan is complete (or failed).
From SNS, one can do the integration to a number of target, or for integration that might require a little bit more involvement, trigger a similar lambda function to notify on findings.
Note
ECR Scan Reporter is written as a Python Library. The Lambda functions simply put the functions in the right order, but you could re-use the Lambda Layer / Python library in your own function and reuse these functions.
Future improvements
One thing that teams using ECR today can do is already to setup lifecycle policies to clean up images that match a number of criteria, which can remove a fair number of images "left behind" which will inevitably get security vulnerabilities reported and therefore create "noise" when the InfoSec teams try to triage and understand what is going on.
Where the implementation of the reporting function is very simple and basic, it would be very easy for anyone to adapt the functions into doing more.
Participate in the roadmap!
This is an open source project that we would love users to get involved, so please help making the reporter better and open new feature requests on GitHub.